import geopandas as gpdimport pandas as pdimport matplotlib.pyplot as pltimport numpy as npimport altair as altfrom sklearn.cluster import KMeansimport refrom wordcloud import WordCloud# Show all columns in dataframespd.set_option('display.max_rows', None)pd.set_option('display.max_columns', None)pd.set_option('display.max_colwidth', None)np.seterr(invalid="ignore");
I concatenate neighborhood and tract names to create 384 sub-neighborhoods that still have recognizable neighborhood names.
Code
# Copying the DataFrametract = phl_tract_proj.copy()# Concatenating 'neighborhood_name' and 'tract_id' into a new column 'nb_name'tract['nb_name'] = tract['neighborhood_name'] +" "+ tract['tract_id'].astype(str)tract["nb_name"].head()
0 Center City East 01
1 Center City East 02
2 Center City West 01
3 Center City West 02
4 Center City West 03
Name: nb_name, dtype: object
I calculate areas for each neighborhood so we can later calculate counts of amenities by square mile
Code
tract = tract.copy()# Calculate area in square meterstract['area_m2'] = tract['geometry'].area# Convert area to square miles (1 square mile = 2,589,988.11 square meters)tract['area_mi2'] = tract['area_m2'] /27878400
# Filter and create a copy to avoid SettingWithCopyWarningfood_desc = restaurants.copy()# Create a new column 'desc_1'food_desc["desc_1"] = food_desc['alias'].str.split(',').str[0].str.strip().str.lower()food_desc["desc_2"] = food_desc['alias'].str.split(',').str[1].str.strip().str.lower()food_desc["desc_3"] = food_desc['alias'].str.split(',').str[2].str.strip().str.lower()
Code
len(food_desc)
2697
First word in “alias”
Code
# Group by 'desc_1' and count, then convert to DataFramefood_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
desc_1
count
108
pizza
320
36
chinese
198
118
restaurants
182
45
delis
161
124
seafood
101
17
breakfast_brunch
88
77
hotdogs
84
100
newamerican
81
122
sandwiches
77
58
fooddeliveryservices
75
Second word in “alias”
Code
# Group by 'desc_2' and count, then convert to DataFramefood_desc.groupby("desc_2").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
desc_2
count
111
sandwiches
120
12
breakfast_brunch
86
64
hotdogs
79
17
burgers
78
112
seafood
73
28
chicken_wings
66
131
tradamerican
65
72
italian
44
98
pizza
42
27
cheesesteaks
41
Third word in “alias”
Code
# Group by 'desc_3' and count, then convert to DataFramefood_desc.groupby("desc_3").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
desc_3
count
83
sandwiches
124
97
tradamerican
61
20
chicken_wings
41
50
hotdogs
39
10
breakfast_brunch
38
13
burgers
33
25
coffee
30
31
delis
26
84
seafood
26
49
hotdog
23
Replace description 1 with description 2 when description 1 is irrelevant
Words like “restaurant” and “fooddeliveryservices” don’t tell us what kind of food is served. Let’s replace the description in these cases with something more descriptive.
In these cases we can search for restaurants where the first word isn’t descriptive, then replace the desc_1 with desc_2.
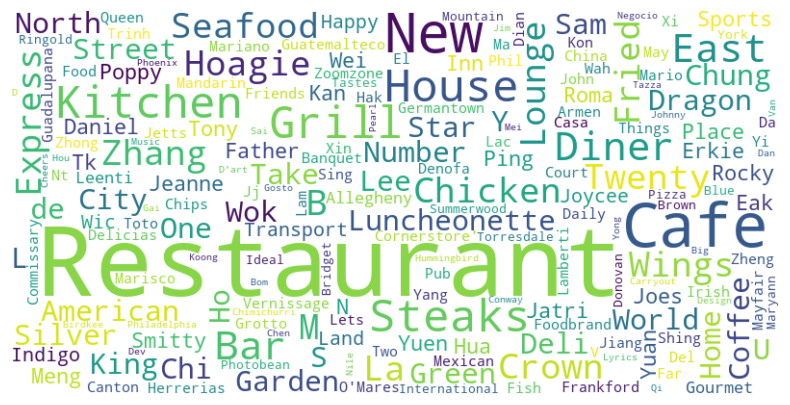
Unfortunately this didn’t replace “restaurant”. Restaurants with only “restaurants” as the first word in their alias usually don’t have other descriptive words. This shows that “restaurant” is the default. This calls for another approach.
By inspecting the names of restaurants lacking descriptions, we can parse out some common categories.
Code
restaurant_cloud = food_desc[food_desc["desc_1"] =="restaurants"]# Concatenate all text in the columntext =' '.join(restaurant_cloud['name'].dropna())# Create the word cloudwordcloud = WordCloud(width=800, height=400, background_color ='white').generate(text)# Display the word cloud using matplotlibplt.figure(figsize=(10, 5))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.show()
Code
# Define the mappingkeyword_mapping = {'yuen': 'chinese','ping': 'chinese','zhong': 'chinese','china': 'chinese',"chinese": "chinese",'canton': 'chinese','wok': 'chinese','lee': 'chinese','china': 'chinese','zhang': 'chinese','chung': 'chinese','dragon': 'chinese','meng': 'chinese','xin': 'chinese','hua': 'chinese','ping': 'chinese','hua': 'chinese','meng': 'chinese','yi': 'chinese','xi': 'chinese','lam': 'chinese','zhang': 'chinese','wei': 'chinese','salad': 'salad','pizza': 'pizza','grill': 'grill',"steak": "grill",'sushi': 'japanese','chicken': 'chicken','pizzeria': 'pizza','pizza': 'pizza','bbg': 'bbq','hoagie': 'sandwich','steaks': 'sandwich','coffee': 'cafe', 'cafe': 'cafe','diner': 'american','luncheonette': 'american','wings': 'wings','deli': 'deli','mexican': 'latin','guadalupana': 'latin','guatamelteco': 'latin','fish': 'seafood','casa': 'latin'}# Function to find the keyword and return the corresponding desc_2 valuedef map_keyword_to_desc(name, mapping):for keyword, desc in mapping.items():if re.search(re.escape(keyword), name, re.IGNORECASE):return descreturnNone# Define the list of specific valuesspecific_values = ["food trucks", "fooddeliveryservices", "bars", "grocery", "restaurants"]# Define the combined condition: desc_2 is NA or in the list of specific valuescondition_combined = food_desc['desc_2'].isna() | food_desc['desc_1'].isin(specific_values)# Apply the function to update desc_2 based on the combined conditionfood_desc.loc[condition_combined, 'desc_1'] = food_desc.loc[condition_combined, 'name'].apply(lambda x: map_keyword_to_desc(x, keyword_mapping))
Identify fast food/chain restaurants
Override desc_1 with “fastfood” for major chain restaurants.
Take the descriptions with frequency < 6 and replace the string with the second term in alias
Code
desc_counts = food_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False)# Filter for 'desc_1' values where count is less than 6desc_less_than_six = desc_counts[desc_counts['count'] <6]['desc_1']# Convert the filtered results to a listdesc_list = desc_less_than_six.tolist()# replace desc_1 with desc_2 where desc_1 is in the list of descriptions with frequency < 6food_desc.loc[food_desc['desc_1'].isin(desc_list), 'desc_1'] = food_desc['desc_2']
# Filter and create a copy to avoid SettingWithCopyWarningparks_desc = parks.copy()# Create a new column 'desc_1'parks_desc["desc_1"] = parks_desc['alias'].str.split(',').str[0].str.strip().str.lower()parks_desc["desc_2"] = parks_desc['alias'].str.split(',').str[1].str.strip().str.lower()parks_desc["desc_3"] = parks_desc['alias'].str.split(',').str[2].str.strip().str.lower()
First word in ‘alias’
Code
# Group by 'desc_1' and count, then convert to DataFrameparks_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(100)
desc_1
count
19
parks
150
15
landmarks
36
21
playgrounds
25
7
dog_parks
23
13
hiking
17
24
recreation
9
12
gardens
7
25
skate_parks
6
28
tennis
4
11
football
4
3
basketballcourts
2
6
discgolf
2
14
kids_activities
2
17
museums
2
18
nonprofit
2
23
rafting
2
20
pets
1
26
stadiumsarenas
1
22
publicart
1
27
swimmingpools
1
0
amateursportsteams
1
16
localflavor
1
1
bars
1
10
fishing
1
9
farms
1
8
farmersmarket
1
5
climbing
1
4
bikes
1
2
baseballfields
1
29
theater
1
Filter for categories where frequency ≥ 5
Code
park_desc_1 = parks_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(9)top_park_desc =list(park_desc_1["desc_1"])# remove historical landmarkstop_park_desc.remove('landmarks')# filter for obs in the list of top descriptionsparks_desc = parks_desc[parks_desc["desc_1"].isin(top_park_desc)]parks_desc.head(10)
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
0
Cedar Park
4.5
50th St & Baltimore Ave
parks
Parks
POINT (2677006.643 234133.514)
parks
NaN
NaN
1
Chester Avenue Dog Park
3.5
801 S 48th St
dog_parks
Dog Parks
POINT (2678024.964 234174.704)
dog_parks
NaN
NaN
2
Malcolm X Park
4.0
51ST And Pine St
parks
Parks
POINT (2676187.013 235721.062)
parks
NaN
NaN
3
Barkan Park
3.0
4936 Spruce St
parks, playgrounds
Parks, Playgrounds
POINT (2677109.530 236278.545)
parks
playgrounds
NaN
4
Clark Park Dog Bowl
4.5
43rd & Chester
dog_parks
Dog Parks
POINT (2680815.785 234312.734)
dog_parks
NaN
NaN
5
Clark Park
4.5
43RD And Baltimore
parks
Parks
POINT (2680756.007 234729.865)
parks
NaN
NaN
6
Greys Ferry Cresent Skatepark
5.0
3600 Grays Ferry Ave
skate_parks
Skate Parks
POINT (2683004.637 231400.562)
skate_parks
NaN
NaN
7
Grays Ferry Crescent
4.0
parks
Parks
POINT (2682813.782 232182.835)
parks
NaN
NaN
8
Lanier Dog Park
4.0
2911 Tasker St
dog_parks
Dog Parks
POINT (2685221.027 229056.524)
dog_parks
NaN
NaN
9
Saunder's Green
3.5
300-50 Saunders Ave
parks
Parks
POINT (2683400.920 238616.685)
parks
NaN
NaN
Education
Code
# Filter and create a copy to avoid SettingWithCopyWarningedu_desc = education.copy()# Create a new column 'desc_1'edu_desc["desc_1"] = edu_desc['alias'].str.split(',').str[0].str.strip().str.lower()edu_desc["desc_2"] = edu_desc['alias'].str.split(',').str[1].str.strip().str.lower()edu_desc["desc_3"] = edu_desc['alias'].str.split(',').str[2].str.strip().str.lower()
First word in alias
Code
# Group by 'desc_1' and count, then convert to DataFrameedu_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(20)
desc_1
count
14
childcare
91
29
elementaryschools
86
66
preschools
62
17
collegeuniv
55
43
highschools
33
26
driving_schools
31
28
educationservices
25
75
specialtyschools
23
81
theater
17
6
artschools
15
19
cosmetology_schools
14
83
tutoring
13
3
artclasses
13
27
education
12
22
dance_schools
10
86
vocation
9
23
dancestudio
8
68
privatetutors
7
49
montessori
7
20
cprclasses
7
Filter for frequency ≥ 6
Code
edu_desc_1 = edu_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(18)top_edu_desc =list(edu_desc_1["desc_1"])# remove historical landmarkstop_edu_desc.remove('theater')# filter for obs in the list of top descriptionsedu_desc_1 = edu_desc[edu_desc["desc_1"].isin(top_edu_desc)]edu_desc.head(10)
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
0
BellyWise
5.0
NaN
midwives, specialtyschools
Midwives, Specialty Schools
POINT (2676169.939 231988.984)
midwives
specialtyschools
NaN
1
Limitless CPR
5.0
NaN
cprclasses
CPR Classes
POINT (2677042.522 231394.414)
cprclasses
NaN
NaN
2
Michele Judge
5.0
4919 Pentridge St
jewelryrepair, artclasses, jewelry
Jewelry Repair, Art Classes, Jewelry
POINT (2677304.635 233898.273)
jewelryrepair
artclasses
jewelry
3
Kipp West Philadelphia Prep Charter
1.0
5900 Baltimore Ave
specialed
Special Education
POINT (2671666.162 232636.864)
specialed
NaN
NaN
4
Beulah Baptist Christian Day School
2.0
5001 Spruce St
elementaryschools, preschools
Elementary Schools, Preschools
POINT (2677065.563 236331.076)
elementaryschools
preschools
NaN
5
The Academy of Industrial Arts
5.0
6328 Paschall Ave
vocation, electricians
Vocational & Technical School, Electricians
POINT (2674851.743 225884.662)
vocation
electricians
NaN
6
TYLII
3.0
5124 Walnut St
preschools, childcare
Preschools, Child Care & Day Care
POINT (2676415.568 237130.841)
preschools
childcare
NaN
7
University of the Sciences
3.0
600 S 43rd St
collegeuniv
Colleges & Universities
POINT (2681062.408 233555.127)
collegeuniv
NaN
NaN
8
All Around This World
5.0
4336 Pine St
educationservices
Educational Services
POINT (2680347.395 235381.376)
educationservices
NaN
NaN
9
Jubilee School
3.0
4211 Chester Ave
highschools
Middle Schools & High Schools
POINT (2681043.809 234475.721)
highschools
NaN
NaN
Grocery
Code
# Filter and create a copy to avoid SettingWithCopyWarninggrocery_desc = grocery.copy()# Create a new column 'desc_1'grocery_desc["desc_1"] = grocery_desc['alias'].str.split(',').str[0].str.strip().str.lower()grocery_desc["desc_2"] = grocery_desc['alias'].str.split(',').str[1].str.strip().str.lower()grocery_desc["desc_3"] = grocery_desc['alias'].str.split(',').str[2].str.strip().str.lower()
Code
grocery_desc.head()
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
0
Kim A Grocery & Deli
1.0
1840 S 58th St
grocery
Grocery
POINT (2675396.135 229529.164)
grocery
NaN
NaN
1
S and J Seafood
4.0
713 S 52nd St
seafoodmarkets, grocery
Seafood Markets, Grocery
POINT (2675793.250 234207.384)
seafoodmarkets
grocery
NaN
2
Mariposa Food Co-op
4.0
4824 Baltimore Ave
grocery, healthmarkets
Grocery, Health Markets
POINT (2677563.153 234052.277)
grocery
healthmarkets
NaN
3
Jennifer Grocery
2.5
4824 Chester Ave
grocery, convenience
Grocery, Convenience Stores
POINT (2678754.671 232771.760)
grocery
convenience
NaN
4
Fu-Wah Mini Market
4.5
810 S 47th St
convenience, sandwiches, grocery
Convenience Stores, Sandwiches, Grocery
POINT (2678571.989 234207.924)
convenience
sandwiches
grocery
Nightlife
Code
# Filter and create a copy to avoid SettingWithCopyWarningnight_desc = nightlife.copy()# Create a new column 'desc_1'night_desc["desc_1"] = night_desc['alias'].str.split(',').str[0].str.strip().str.lower()night_desc["desc_2"] = night_desc['alias'].str.split(',').str[1].str.strip().str.lower()night_desc["desc_3"] = night_desc['alias'].str.split(',').str[2].str.strip().str.lower()
Code
night_desc.head()
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
0
Pentridge Station Beer Garden
4.5
5116 Pentridge St
beergardens
Beer Gardens
POINT (2676581.781 233167.788)
beergardens
NaN
NaN
1
720 Bistro
4.0
720 S.52nd st
seafood, breakfast_brunch, cocktailbars
Seafood, Breakfast & Brunch, Cocktail Bars
POINT (2675620.054 234102.746)
seafood
breakfast_brunch
cocktailbars
2
Bayou
4.5
5025 Baltimore Ave
lounges
Lounges
POINT (2676525.799 234061.840)
lounges
NaN
NaN
3
Booker's Restaurant and Bar
3.5
5021 Baltimore Ave
bars, breakfast_brunch, tradamerican
Bars, Breakfast & Brunch, American
POINT (2676559.222 234070.085)
bars
breakfast_brunch
tradamerican
4
The Wine Garden
4.5
5019 Baltimore Ave
wine_bars
Wine Bars
POINT (2676563.551 234060.148)
wine_bars
NaN
NaN
Alias
Code
# Group by 'desc_1' and count, then convert to DataFramenight_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
desc_1
count
6
bars
172
86
sportsbars
78
75
pubs
71
34
divebars
53
61
lounges
49
100
tradamerican
49
67
newamerican
47
23
cocktailbars
39
47
hookah_bars
28
66
musicvenues
28
Code
# Group by 'desc_2' and count, then convert to DataFramenight_desc.groupby("desc_2").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
desc_2
count
7
bars
93
103
tradamerican
61
93
sportsbars
48
25
cocktailbars
43
69
newamerican
39
62
lounges
28
86
seafood
28
68
musicvenues
25
80
pubs
24
11
beerbar
19
Code
# Group by 'desc_3' and count, then convert to DataFramenight_desc.groupby("desc_3").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
night_desc_1 = night_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(9)top_night_desc =list(night_desc_1["desc_1"])# filter for obs in the list of top descriptionsnight_desc = night_desc[night_desc["desc_1"].isin(top_night_desc)]night_desc.head(10)
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
1
720 Bistro
4.0
720 S.52nd st
seafood, breakfast_brunch, cocktailbars
Seafood, Breakfast & Brunch, Cocktail Bars
POINT (2675620.054 234102.746)
cocktailbars
cocktailbars
cocktailbars
2
Bayou
4.5
5025 Baltimore Ave
lounges
Lounges
POINT (2676525.799 234061.840)
lounges
NaN
NaN
3
Booker's Restaurant and Bar
3.5
5021 Baltimore Ave
bars, breakfast_brunch, tradamerican
Bars, Breakfast & Brunch, American
POINT (2676559.222 234070.085)
bars
tradamerican
tradamerican
4
The Wine Garden
4.5
5019 Baltimore Ave
wine_bars
Wine Bars
POINT (2676563.551 234060.148)
wine_bars
NaN
NaN
5
Carbon Copy
4.5
701 S 50th St
breweries, pizza, bars
Breweries, Pizza, Bars
POINT (2676997.957 233927.765)
bars
bars
bars
6
Dock Street Cannery and Tasting Room
4.0
705 S 50th St
beerbar, lounges
Beer Bar, Lounges
POINT (2677046.168 233912.738)
beerbar
lounges
NaN
7
Trendsetters Bar & Lounge
3.5
5301 Woodland Ave
burgers, lounges, wraps
Burgers, Lounges, Wraps
POINT (2678439.957 230236.502)
lounges
lounges
wraps
8
The Barn
3.5
4901 Catharine St
poolhalls, sportsbars, divebars
Pool Halls, Sports Bars, Dive Bars
POINT (2677365.738 234212.623)
sportsbars
sportsbars
divebars
9
Eris Temple
4.0
602 S 52nd St
musicvenues
Music Venues
POINT (2675702.055 234852.608)
musicvenues
NaN
NaN
10
Dahlak
3.5
4708 Baltimore Ave
ethiopian, divebars
Ethiopian, Dive Bars
POINT (2678487.076 234234.642)
divebars
divebars
NaN
Entertainment
Code
# Filter and create a copy to avoid SettingWithCopyWarningentertain_desc = entertainment.copy()# Create a new column 'desc_1'entertain_desc["desc_1"] = entertain_desc['alias'].str.split(',').str[0].str.strip().str.lower()entertain_desc["desc_2"] = entertain_desc['alias'].str.split(',').str[1].str.strip().str.lower()entertain_desc["desc_3"] = entertain_desc['alias'].str.split(',').str[2].str.strip().str.lower()
Code
entertain_desc.head()
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
0
Noam Osband
5.0
NaN
musicians
Musicians
POINT (2676083.283 232370.886)
musicians
NaN
NaN
1
Ceramic Concept
5.0
5015 Baltimore Ave
galleries
Art Galleries
POINT (2676620.711 234054.592)
galleries
NaN
NaN
2
Eris Temple
4.0
602 S 52nd St
musicvenues
Music Venues
POINT (2675702.055 234852.608)
musicvenues
NaN
NaN
3
Baltimore Avenue Dollar Stroll
5.0
4800 Baltimore Ave
unofficialyelpevents, festivals
Unofficial Yelp Events, Festivals
POINT (2677842.004 234135.971)
unofficialyelpevents
festivals
NaN
4
Curio Theatre Company
4.5
815 S 48th St
theater
Performing Arts
POINT (2678192.432 234160.959)
theater
NaN
NaN
Alias
Code
# Group by 'desc_1' and count, then convert to DataFrameentertain_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
entertain_desc_1 = entertain_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False)entertain_desc_1 = entertain_desc_1[entertain_desc_1['count'] >=5]top_entertain_desc =list(entertain_desc_1["desc_1"])top_entertain_desc.remove('psychics')# filter for obs in the list of top descriptionsentertain_desc = entertain_desc[entertain_desc["desc_1"].isin(top_entertain_desc)]
# Filter and create a copy to avoid SettingWithCopyWarningshop_desc = shopping.copy()# Create a new column 'desc_1'shop_desc["desc_1"] = shop_desc['alias'].str.split(',').str[0].str.strip().str.lower()shop_desc["desc_2"] = shop_desc['alias'].str.split(',').str[1].str.strip().str.lower()shop_desc["desc_3"] = shop_desc['alias'].str.split(',').str[2].str.strip().str.lower()
Code
shop_desc.head()
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
0
Rite Aid
2.0
5214-30 Baltimore Ave
drugstores, convenience
Drugstores, Convenience Stores
POINT (2675264.630 233732.096)
drugstores
convenience
NaN
1
Ajah Creative Sweets And Treats & More
5.0
NaN
desserts, cupcakes, giftshops
Desserts, Cupcakes, Gift Shops
POINT (2677939.712 232732.831)
desserts
cupcakes
giftshops
2
Ceramic Concept
5.0
5015 Baltimore Ave
galleries
Art Galleries
POINT (2676620.711 234054.592)
galleries
NaN
NaN
3
VIX Emporium
4.5
5009 Baltimore Ave
artsandcrafts, childcloth, jewelry
Arts & Crafts, Children's Clothing, Jewelry
POINT (2676676.410 234091.659)
artsandcrafts
childcloth
jewelry
4
Michele Judge
5.0
4919 Pentridge St
jewelryrepair, artclasses, jewelry
Jewelry Repair, Art Classes, Jewelry
POINT (2677304.635 233898.273)
jewelryrepair
artclasses
jewelry
Alias
Code
# Group by 'desc_1' and count, then convert to DataFrameshop_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
desc_1
count
32
drugstores
234
142
womenscloth
114
69
jewelry
90
31
discountstore
87
49
galleries
84
48
furniture
74
113
shoes
68
29
deptstores
56
86
menscloth
50
11
bookstores
41
Code
# Group by 'desc_2' and count, then convert to DataFrameshop_desc.groupby("desc_2").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
desc_2
count
24
convenience
95
0
accessories
67
139
womenscloth
66
81
menscloth
51
48
furniture
38
65
jewelry
35
100
pharmacy
34
35
discountstore
32
49
galleries
29
61
homedecor
27
Code
# Group by desc_3' and count, then convert to DataFrameshop_desc.groupby("desc_3").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
# remove drugstores and grocerytop_shop_desc.remove('drugstores')top_shop_desc.remove('grocery')# filter for obs in the list of top descriptionsshop_desc = shop_desc[shop_desc["desc_1"].isin(top_shop_desc)]
Code
# Define the mapping dictionarydesc_mapping = {"mattresses": "furniture","kitchenandbath": "furniture","rugs": "homedecor","hats": "accessories","watch_repair": "accessories"}# Replace desc_1 values using the mapping dictionaryshop_desc.loc[:, 'desc_1'] = shop_desc['desc_1'].replace(desc_mapping)shop_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(20)
desc_1
count
17
womenscloth
114
10
jewelry
90
5
discountstore
87
7
galleries
84
6
furniture
74
13
shoes
68
4
deptstores
56
11
menscloth
50
2
bookstores
41
0
accessories
40
15
thrift_stores
36
1
antiques
31
8
giftshops
24
12
selfstorage
23
9
homedecor
23
3
childcloth
21
14
sportswear
20
16
vintage
19
Healthcare
Code
# Filter and create a copy to avoid SettingWithCopyWarninghealth_desc = healthcare.copy()# Create a new column 'desc_1'health_desc["desc_1"] = health_desc['alias'].str.split(',').str[0].str.strip().str.lower()health_desc["desc_2"] = health_desc['alias'].str.split(',').str[1].str.strip().str.lower()health_desc["desc_3"] = health_desc['alias'].str.split(',').str[2].str.strip().str.lower()
Alias
Code
# Group by 'desc_1' and count, then convert to DataFramehealth_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
# filter for obs in the list of top descriptionshealth_desc = health_desc[health_desc["desc_1"].isin(top_health_desc)]
Historic landmarks
Code
# Filter and create a copy to avoid SettingWithCopyWarninghistoric_desc = historic.copy()# Create a new column 'desc_1'historic_desc["desc_1"] = historic_desc['alias'].str.split(',').str[0].str.strip().str.lower()historic_desc["desc_2"] = historic_desc['alias'].str.split(',').str[1].str.strip().str.lower()historic_desc["desc_3"] = historic_desc['alias'].str.split(',').str[2].str.strip().str.lower()
Alias
Code
# Group by 'desc_1' and count, then convert to DataFramehistoric_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
# Group by 'desc_1' and count, then convert to DataFramekids_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
arts_desc = arts.copy()# Create a new column 'desc_1'arts_desc["desc_1"] = arts_desc['alias'].str.split(',').str[0].str.strip().str.lower()arts_desc["desc_2"] = arts_desc['alias'].str.split(',').str[1].str.strip().str.lower()arts_desc["desc_3"] = arts_desc['alias'].str.split(',').str[2].str.strip().str.lower()arts_desc.head()
name
rating
address
alias
title
geometry
desc_1
desc_2
desc_3
0
Curio Theatre Company
4.5
815 S 48th St
theater
Performing Arts
POINT (2678192.432 234160.959)
theater
NaN
NaN
1
Studio 34
4.5
4522 Baltimore Ave
yoga, pilates, theater
Yoga, Pilates, Performing Arts
POINT (2679553.196 234477.061)
yoga
pilates
theater
2
Painted Bride Art Center
3.5
5212 Market St
theater, venues
Performing Arts, Venues & Event Spaces
POINT (2676029.704 238278.040)
theater
venues
NaN
3
The Rotunda
4.5
4014 Walnut St
musicvenues, theater
Music Venues, Performing Arts
POINT (2682266.656 236480.866)
musicvenues
theater
NaN
4
Penn Live Arts
4.0
3680 Walnut St
theater, jazzandblues, musicvenues
Performing Arts, Jazz & Blues, Music Venues
POINT (2684326.329 236037.832)
theater
jazzandblues
musicvenues
Alias
Code
# Group by 'desc_1' and count, then convert to DataFramearts_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
# Group by 'desc_1' and count, then convert to DataFramebeauty_desc.groupby("desc_1").size().reset_index(name='count').sort_values("count", ascending =False).head(10)
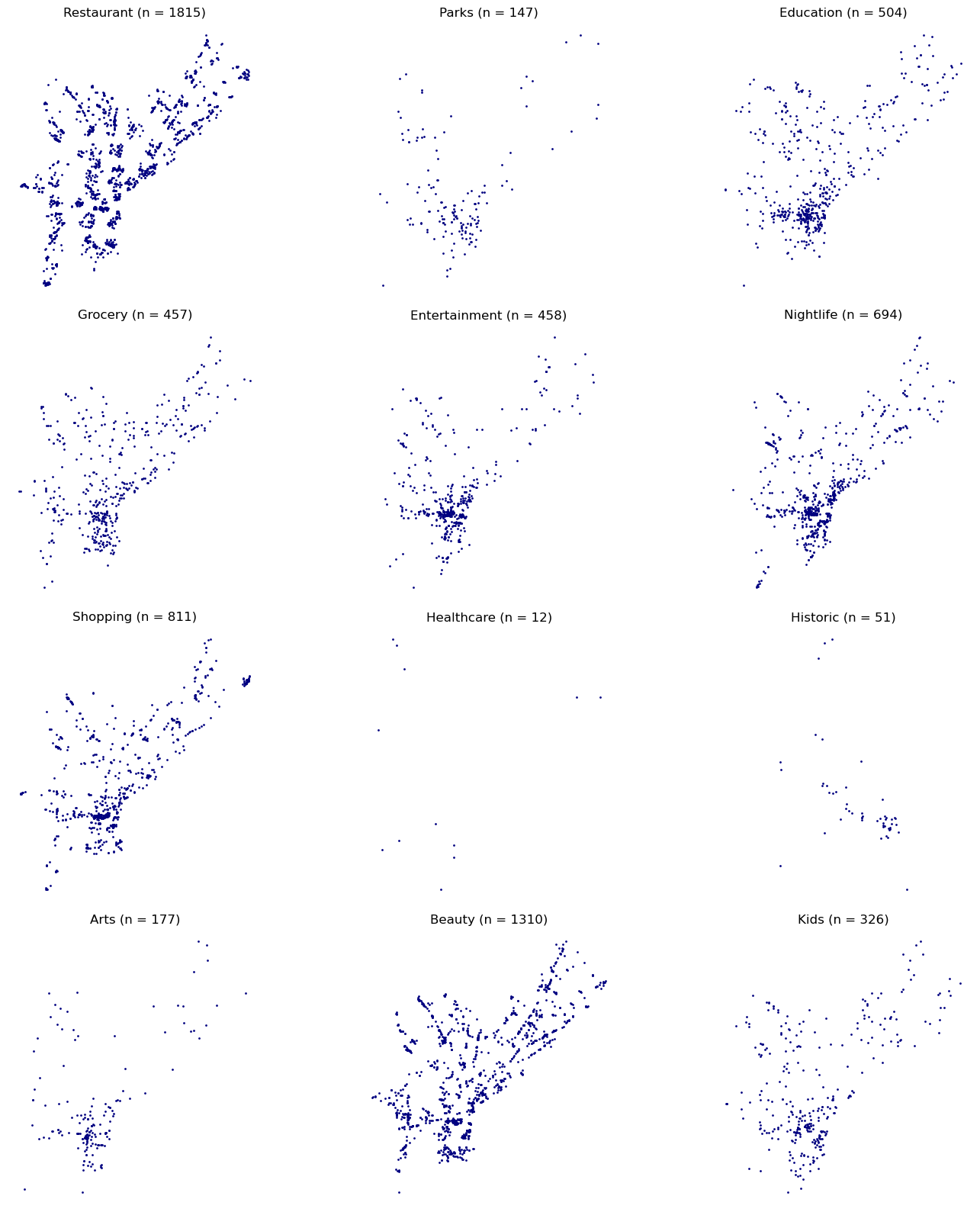
# Extract unique business typesbusiness_types = amenities_phl_gdf['type'].unique()# Determine the number of rows and columns for the subplotsn_rows =len(business_types) //3+ (len(business_types) %3>0)fig, axes = plt.subplots(n_rows, 3, figsize=(15, n_rows *4))# Flatten the axes array for easy loopingaxes = axes.flatten()# Create a map for each business typefor i, business_type inenumerate(business_types):# Filter data for the current business type subset = amenities_phl_gdf[amenities_phl_gdf['type'] == business_type]# Get count for the current business type count = amenities_grouped[amenities_grouped['type'] == business_type]['count'].values[0]# Plotting with transparency subset.plot(ax=axes[i], color='navy', markersize=1, alpha=1)# Set title with count (n = count) axes[i].set_title(f"{business_type.capitalize()} (n = {count})")# Customizations: Remove boxes, axis ticks, and labels axes[i].set_axis_off()# Remove unused subplotsfor j inrange(i+1, len(axes)): fig.delaxes(axes[j])# Adjust layoutplt.tight_layout()# Display the panel of mapsplt.show()
Intersect with neighborhoods
Code
amenities_neighborhood = gpd.sjoin(amenities_phl_gdf, neigh, how ="left", predicate ="intersects")amenities_tract = gpd.sjoin(amenities_phl_gdf, tract, how ="left", predicate ="intersects")
amenities_neigh_group_gdf = amenities_neigh_group.merge(neigh, on ="nb_name", how ="left")amenities_tract_group_gdf = amenities_tract_group.merge(tract, on ="nb_name", how ="left")
Make this Notebook Trusted to load map: File -> Trust Notebook
Code
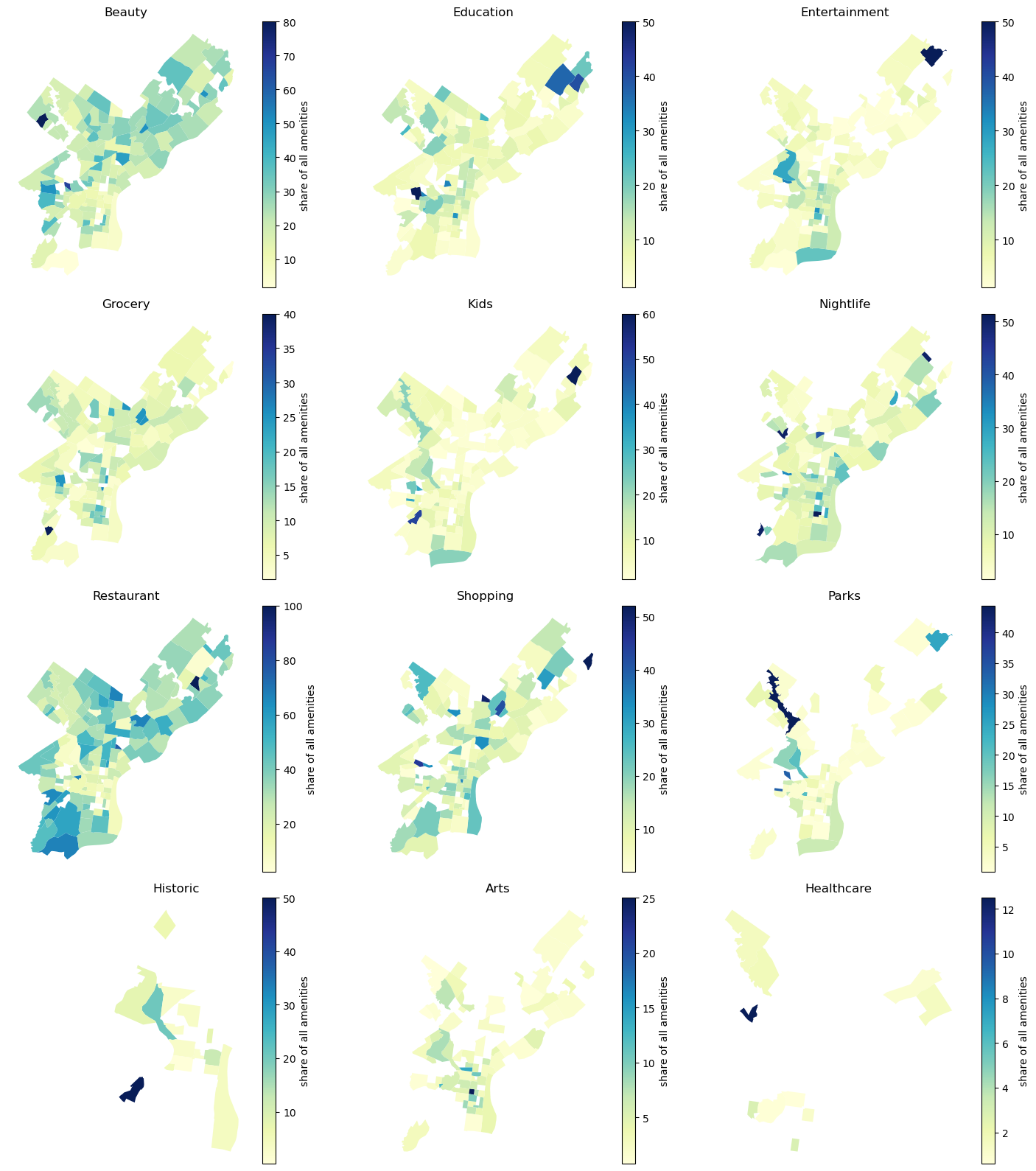
# Extract unique typesamenity_types = amenities_nb['type'].unique()# Determine the number of rows and columns for the subplotsn_rows =len(amenity_types) //3+ (len(amenity_types) %3>0)fig, axes = plt.subplots(n_rows, 3, figsize=(15, n_rows *4))# Flatten the axes array for easy loopingaxes = axes.flatten()# Create a choropleth map for each amenity typefor i, amenity_type inenumerate(amenity_types):# Filter data for the current amenity type subset = amenities_nb[amenities_nb['type'] == amenity_type]# Plotting subset.plot(column='pct_share', ax=axes[i], legend=True, legend_kwds={'label': "share of all amenities"}, cmap='YlGnBu')# Set title axes[i].set_title(amenity_type.capitalize())# Remove boxes, axis ticks, and axis labels axes[i].set_axis_off()# Remove unused subplotsfor j inrange(i+1, len(axes)): fig.delaxes(axes[j])# Adjust layoutplt.tight_layout()# Display the panel of mapsplt.show()
# spreading the dataamenities_nb_wide = amenities_nb.pivot_table(index='nb_name', columns='type', values='pct_share', aggfunc=np.mean).fillna(0)
Code
# Calculating the correlation matrixcorrelation_matrix = amenities_nb_wide.corr()import altair as alt# Reset index to convert the index into a column for Altairheatmap_data = correlation_matrix.reset_index().melt('type', var_name='type2', value_name='correlation')# Create the heatmapheatmap = alt.Chart(heatmap_data).mark_rect().encode( x='type:N', y='type2:N', color='correlation:Q')# Add text to each celltext = heatmap.mark_text(baseline='middle').encode( text=alt.Text('correlation:Q', format='.2f'), color=alt.condition( alt.datum.correlation >0.75, alt.value('white'), alt.value('black') ))# Display the chartchart = (heatmap + text).properties(width=600, height=600)chart
Cluster analysis
Code
from sklearn.preprocessing import MinMaxScaler, RobustScalerfrom sklearn.preprocessing import StandardScalerscaler = StandardScaler()
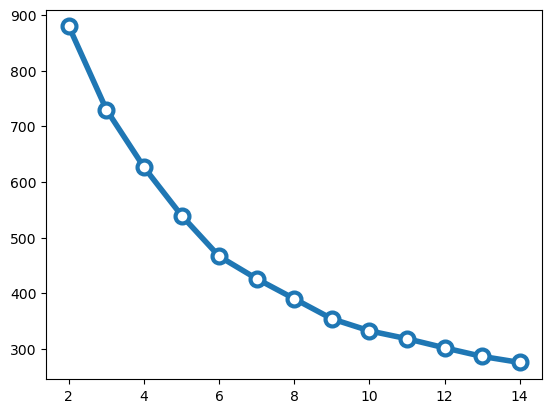
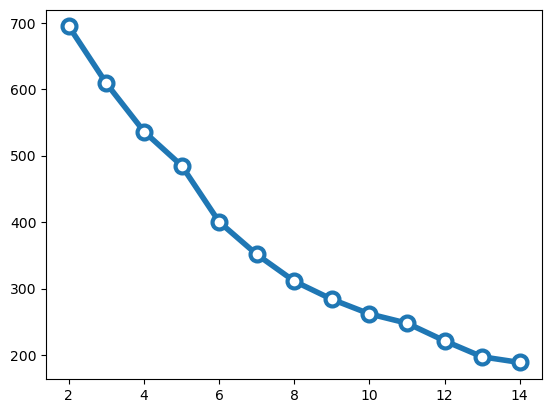
# Number of clusters to try outn_clusters =list(range(2, 15))# Run kmeans for each value of kinertias = []for k in n_clusters:# Initialize and run kmeans = KMeans(n_clusters=k, n_init=20) kmeans.fit(amenities_nb_scaled)# Save the "inertia" inertias.append(kmeans.inertia_)# Plot it!plt.plot(n_clusters, inertias, marker='o', ms=10, mfc='white', lw=4, mew=3);from kneed import KneeLocator# Initialize the knee algorithmkn = KneeLocator(n_clusters, inertias, curve='convex', direction='decreasing')# Print out the knee print(kn.knee)
restaurant = food_desc[["name", "desc_1"]]nb_gdf = amenities_neighborhood[["nb_name", "name", "rating"]]restaurants_nb_gdf = restaurant.merge(nb_gdf, on ="name", how ="left")
Code
restaurants_nb_grouped = restaurants_nb_gdf.groupby(["nb_name", "desc_1"]).size().reset_index(name="count")# Sort within each neighborhood group by count in descending orderrestaurants_nb_grouped = restaurants_nb_grouped.sort_values(by=["nb_name", "count"], ascending=[True, False])restaurants_nb_grouped.head()
nb_name
desc_1
count
1
Academy Gardens
fastfood
8
0
Academy Gardens
chinese
4
2
Academy Gardens
pizza
1
3
Academy Gardens
seafood
1
4
Academy Gardens
venues
1
Code
restaurants_nb_wide = restaurants_nb_grouped.pivot(index='nb_name', columns='desc_1', values='count').reset_index().fillna(0)# Calculating the correlation matrixcorrelation_matrix = restaurants_nb_wide.corr()import altair as alt# Reset index to convert the index into a column for Altairheatmap_data = correlation_matrix.reset_index().melt('desc_1', var_name='desc_2', value_name='correlation')
Code
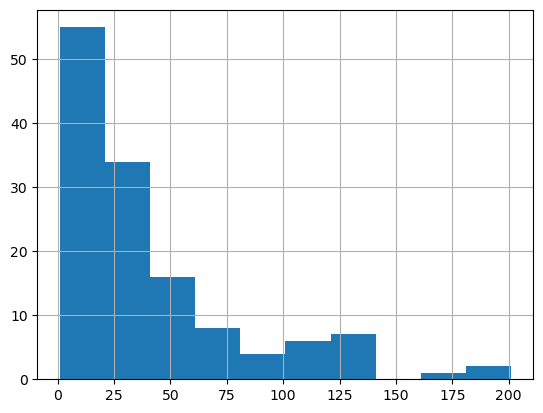
restaurants_total.hist()
<Axes: >
Code
# Calculating the total restaurants for each neighborhoodrestaurants_total = restaurants_nb_wide.set_index('nb_name').sum(axis=1)# Using 'map' to align and assign the total restaurants back to the original DataFramerestaurants_nb_wide["total_restaurants"] = restaurants_nb_wide['nb_name'].map(restaurants_total)restaurants_nb_wide = restaurants_nb_wide[restaurants_nb_wide["total_restaurants"] >10].copy()restaurants_nb_wide.head()
desc_1
nb_name
american
asianfusion
bakeries/cafes
bbq
breakfast_brunch
caribbean
chicken
chinese
cocktailbars
diner/grill
fastfood
halal
indpak
italian
japanese
korean
latin
mediterranean
pizza
salad
sandwiches/delis
seafood
soulfood
venues
vietnamese
total_restaurants
0
Academy Gardens
0.0
0.0
0.0
0.0
0.0
0.0
0.0
4.0
0.0
0.0
8.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
1.0
0.0
0.0
1.0
0.0
1.0
0.0
15.0
1
Airport
2.0
0.0
18.0
0.0
4.0
0.0
2.0
0.0
0.0
3.0
46.0
0.0
0.0
4.0
2.0
0.0
5.0
3.0
4.0
7.0
8.0
7.0
0.0
2.0
0.0
117.0
2
Allegheny West
0.0
0.0
2.0
2.0
0.0
1.0
8.0
6.0
0.0
0.0
86.0
0.0
0.0
0.0
6.0
0.0
0.0
0.0
5.0
0.0
3.0
4.0
1.0
0.0
0.0
124.0
3
Andorra
5.0
1.0
0.0
0.0
0.0
0.0
0.0
1.0
0.0
0.0
31.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
1.0
11.0
0.0
0.0
0.0
0.0
50.0
6
Brewerytown
0.0
0.0
6.0
0.0
1.0
0.0
0.0
3.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
3.0
0.0
2.0
0.0
2.0
0.0
0.0
17.0
Code
# Columns representing different cuisinescuisine_columns = ['bakeries/cafes', 'chicken', 'chinese', 'diner/grill', 'fastfood', "korean",'pizza', 'sandwiches/delis', 'vietnamese', 'total_restaurants']# Convert cuisine counts to percentages of the total restaurantsfor column in cuisine_columns: restaurants_nb_wide[column] = ((restaurants_nb_wide[column] / restaurants_nb_wide['total_restaurants']) *100).round(2)# Check the updated DataFramerestaurants_nb_wide.head()
desc_1
nb_name
american
asianfusion
bakeries/cafes
bbq
breakfast_brunch
caribbean
chicken
chinese
cocktailbars
diner/grill
fastfood
halal
indpak
italian
japanese
korean
latin
mediterranean
pizza
salad
sandwiches/delis
seafood
soulfood
venues
vietnamese
total_restaurants
0
Academy Gardens
0.0
0.0
0.00
0.0
0.0
0.0
0.00
26.67
0.0
0.00
53.33
0.0
0.0
0.0
0.0
0.0
0.0
0.0
6.67
0.0
0.00
1.0
0.0
1.0
0.0
100.0
1
Airport
2.0
0.0
15.38
0.0
4.0
0.0
1.71
0.00
0.0
2.56
39.32
0.0
0.0
4.0
2.0
0.0
5.0
3.0
3.42
7.0
6.84
7.0
0.0
2.0
0.0
100.0
2
Allegheny West
0.0
0.0
1.61
2.0
0.0
1.0
6.45
4.84
0.0
0.00
69.35
0.0
0.0
0.0
6.0
0.0
0.0
0.0
4.03
0.0
2.42
4.0
1.0
0.0
0.0
100.0
3
Andorra
5.0
1.0
0.00
0.0
0.0
0.0
0.00
2.00
0.0
0.00
62.00
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.00
1.0
22.00
0.0
0.0
0.0
0.0
100.0
6
Brewerytown
0.0
0.0
35.29
0.0
1.0
0.0
0.00
17.65
0.0
0.00
0.00
0.0
0.0
0.0
0.0
0.0
0.0
0.0
17.65
0.0
11.76
0.0
2.0
0.0
0.0
100.0
Code
# Create the heatmapheatmap = alt.Chart(heatmap_data).mark_rect().encode( x='desc_1:N', y='desc_2:N', color='correlation:Q')# Add text to each celltext = heatmap.mark_text(baseline='middle').encode( text=alt.Text('correlation:Q', format='.2f'), color=alt.condition( alt.datum.correlation >0.5, alt.value('white'), alt.value('black') ))# Display the chartchart = (heatmap + text).properties(width=1000, height=1000)chart
# Number of clusters to try outn_clusters =list(range(2, 15))# Run kmeans for each value of kinertias = []for k in n_clusters:# Initialize and run kmeans = KMeans(n_clusters=k, n_init=10) kmeans.fit(restaurants_nb_scaled)# Save the "inertia" inertias.append(kmeans.inertia_)# Plot it!plt.plot(n_clusters, inertias, marker='o', ms=10, mfc='white', lw=4, mew=3);from kneed import KneeLocator# Initialize the knee algorithmkn = KneeLocator(n_clusters, inertias, curve='convex', direction='decreasing')# Print out the knee print(kn.knee)
7
Nightlife
Code
nightlife = night_desc[["name", "desc_1"]]nb_gdf = amenities_neighborhood[["nb_name", "name", "rating"]]nightlife_nb_gdf = nightlife.merge(nb_gdf, on ="name", how ="left")
Code
nightlife_nb_grouped = nightlife_nb_gdf.groupby(["nb_name", "desc_1"]).size().reset_index(name="count")# Sort within each neighborhood group by count in descending ordernightlife_nb_grouped = nightlife_nb_grouped.sort_values(by=["nb_name", "count"], ascending=[True, False])nightlife_nb_grouped.head(20)